A Maturity Model for Digital Fraud Resilience

Why a maturity model for digital fraud resilience? Because identifying and preventing fraud in digital services requires collaboration, and successful collaborations require a common language and understanding of how to act on knowledge, along with a map of the landscape. A model, if you will.
Why resilience and not prevention? Because fraudsters are clever and it won’t be eliminated. Our only remedy is to learn and respond as quickly as possible to those clever buggers.
This maturity model was developed from extensive research conducted in 2019 across many government agencies of varying sizes, as part of an effort to introduce known, effective, real-time/ML-based fraud resilience platforming technology. The research found that there was an uneven level of knowledge and understanding across departments that needed to be addressed before we could even talk about the tech. We also found that an incremental approach was needed along with different paths to achieving maturity for different government agencies.
As a result, this maturity model was developed and concieved to be independent of prescription, providing needed flexibility for different use cases across an organisation. Please consider this a map, not a hard-and-fast set of rules.
A definition of maturity
An organisation is considered mature in its digital fraud resilience capability when it has the organisational practices and tools in place that allow it to minimise the effects from a changing landscape, where the rate of change exceeds human capacity. In other words, you’re able to handle a deluge of data to prevent and respond to fraud.
Today, this can be achieved by focusing on three areas of capability:
- Service intervention – the ability to take action during the course of service interaction by tailoring interactions according to confidence level
- Data insight – the ability to capture, make available, and interpret behavioural and operational data
- Coverage – the totality of behavioural events and data points that are captured and the specificity of context of that data
Service intervention
The most expensive time to deal with fraud is after it’s happened.
The goal for service designers is to provide low-friction service to legitimate customers while accounting for the realities of fraud in the digital age.
When to take action (an intervention in fraud-speak) should be considered case-by-case. As a general rule, however, earlier is better.
It’s most important to have considered this as a service is designed, and to be able to explain the thinking behind decisions to various stakeholders.
Let’s look at these intervention types while thinking about cost:
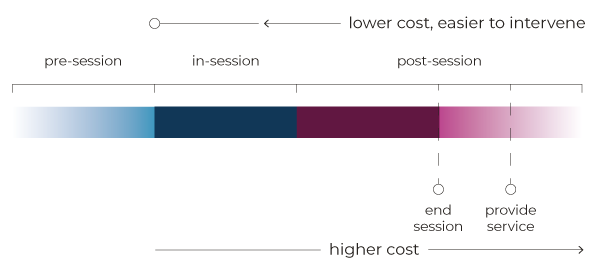
- Pre-session – before engaging a service, authentication is the greatest concern. This is primarily the concern of IDA and cyber security efforts, but has a high degree of overlap with fraud prevention. For instance, past behavioural data such as location and timings from legitimate interactions can be used to discriminate future ones.
- In-session – once identity is established, and transacting begins, anything this is asserted, such as an address to be changed or a bank account to be used that can be verified should. The consequence of this might be negative to the user experience (stopping a session for the wrong reason) or expensive to the service provider (per-use costs associated with commercial data lookups).
- Post-session / pre-service – the end-user has been allowed to complete their user journey, but further checks are done, usually by a human. Delays in service at this point can be problematic for the end-user, so we should constantly be asking ourselves why we weren’t able to determine risk in an automated manner, and look to improve.
- Post-session / post-service – after the session has ended, and the service has been provided. Because fraudsters are always coming up with new and clever exploits, this is inevitable. The question becomes, how quickly can we discover this, and do we have everything in place to have done so, and prevent it from happening again.
Data Insight
When we make use of data from service interactions to evaluate them for risk of fraud (or for compliance which has a lot of overlap), there are two main concerns:
Automated vs Manual When a human has to look at the data, often in disparate sources, especially non-digital, this is the most time-consuming and expensive.
We can automate things, but automation can mean different things. We can set rules and limits to values in digital transactions, or we can apply machine learning.
Rules & Data vs Behaviours Checking expected data values is the most basic thing that we do. Often, these values are strictly set in policy. When we get values out of expected bounds, it’s sometimes difficult to understand if it’s anomalous, an error, or fraud-y.
Risk agents often look at multiple data sources to determine this. Behavioural data can help. That an interaction took place in mere seconds from a country with a history of originating fraud will often say more than just the numerical value of a requested disbursement, which could be well within the rules.
Behaviours alone, however, can lead to false positives, especially as citizens move around globally, and so having access to both is the most valuable.
Data quality The more data is available, the better that machine learning systems can learn. And better than more data is good data. Ensuring that data quality standards are set, agreed, and enforced creates the best foundation for data insight.
It’s very difficult to achieve mature fraud resilience in an organisation that’s struggling with data quality in general. Wherever possible, fraud resilience efforts should work with data transformation efforts to cross-pollinate ideas and ensure that best practices are being shared.
Coverage
Starting at the narrowest point, we can imagine that we have a service that’s digital by default, and that we can capture every interaction, so that it can be assessed for fraud risk. In the best case, the service is designed so that the events that are captured are enriched with metadata that is usable by a specific fraud domain area, but in such a way that the data is usable by other business areas.
Coverage is this ability to provide data in a common, automated, manner, such that it can provide the domain-specific information required by fraud & risk caseworkers
Coverage should be considered at multiple levels:
- are all your services covered?
- how completely is any given service covered?
- what percentage of their data is available for auditing?
- is the audit data specific enough to provide value to fraud investigation
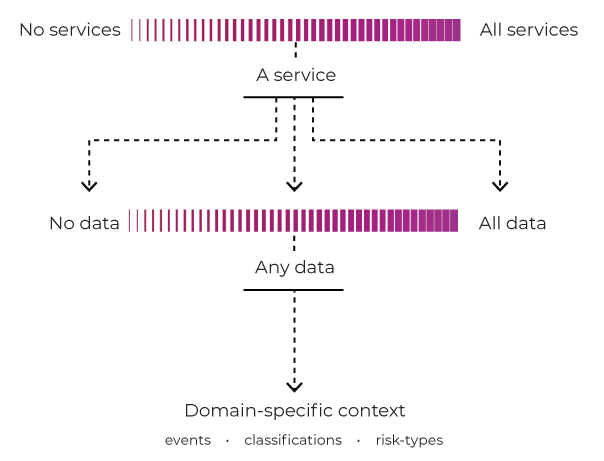
Having no services and no data is obviously out of the question, but we have to consider the ROI on having all data for all services, across all domains, for all circumstances.
Most likely, any organisation will sit somewhere in between, and complete coverage will be over-burdensome. In order to be able to identify behavioural patterns of fraud, however, a high degree of coverage is required, as is the ability to make use of that information.
Achieving Maturity
These capabilities say nothing about how to measure maturity, only what would help in achieving it. Ideally, an organisation can automatically assess fraud risk of any given transaction to identify fraud risks for all its business areas by combining behaviour and business process data, for an acceptable portion of all transactions, in such a way that the costs do not outweigh the benefits.
Consider the following scenarios:
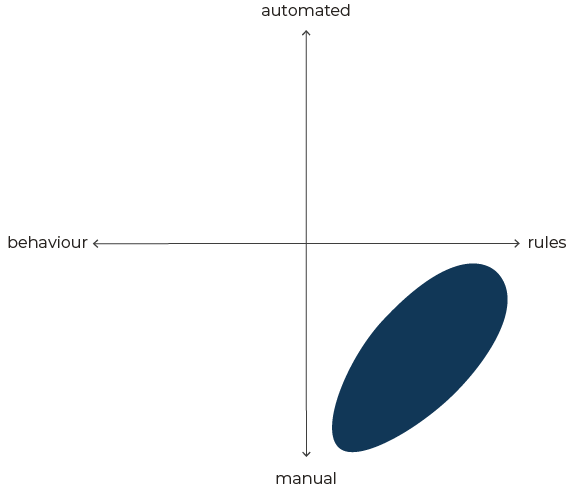
In this first case, a person manually reviews business transactions for fraud risk using known rules, after transactions have completed. This is likely because a service is not digital, or because fraud and risk areas have not been included in digital transformation efforts, so their work is not fully integrated.

In the second case, many of the processes have been automated, and more fully integrated into the service. But we are still relying on applying rules and checking data values. We are not taking advantage of the vast amounts of data that result from digital interactions, such as the time, location, and device that the interaction originates from.
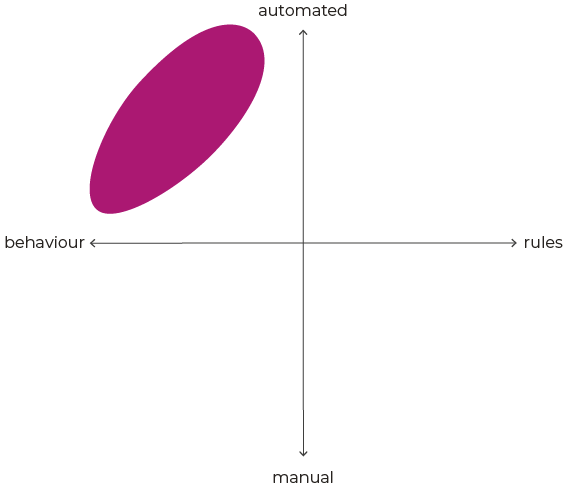
If we are looking at behaviours only, however, we may not be getting the whole picture.
The potential for machine learning & AI
When we're able to access both behaviour, and also inspect the values of the data from digital interactions, we can tell a whole story about what is happening, and this gives us the best chance of identifying fraud. Doing so in an automated way is the domain of artificial intelligence and machine learning. This requires a great amount of good quality data.
This is most valuable in the case of new vectors of attack for fraud where previously established rules fail. The ability to access and mine data in a timely manner can have a large impact on the amount of fraud that is prevented.
But machine learning has its limits – it’s limited by modelling known behaviours. As interactions go fully digital and the data which comprises those streams is created at rates and volumes which exceed human capacity, new forms of fraud are manifesting in forms and patterns which effectively conceal them from both human operatives and trained models. The potential of such analysis may prove impossible to realise until the full potential of artificial intelligence has been brought to bear and AI is able to spot previously undetected fraud patterns as people do through intuition.
Any organisation which anticipates a need for fraud resilient systems needs to begin development efforts immediately. Real-time or near-real time processing won’t be achieved overnight, and few vendors are yet up-to-speed, either with product offers or domain knowledge. That’s because those vendors ultimately rely on high quality data. As the source of that data, you’re the expert.
The ability to leverage operational data for fraud resilience purposes will then determine an organisation’s ability to achieve maturity.
FraudOps, the next step in fraud prevention
We use the phrase “DevOps” to describe well-integrated IT and operations and software development processes. Something like it is required, where fraud prevention, software development, and operations are all well-integrated and work in a continuous flow of work and improvement. Digital services should not have to think too hard about fraud and risk, because a majority of the tools and processes are in place before they begin.
A mature fraud-protection capability can be considered conducive to Fraud Ops when an organisation’s platforming provides the following tools:
- default system event capture -- across-the board defaults
- bespoke system event capture -- services can extend features to provide custom data
- data science capability -- tools and automatic feeds of data into ML models
- watchlists -- configuration for rules and specific events
- automated workflow, especially feeding back efficacy for rules and models
- data quality & checking -- first line of defence is standardised and shared
- integration to services through configuration -- turnkey and de-facto for all new services
- automated third-party data ingestion -- especially for legacy systems
- APIs / exchange of data across organisational boundaries for fraud resilience purposes
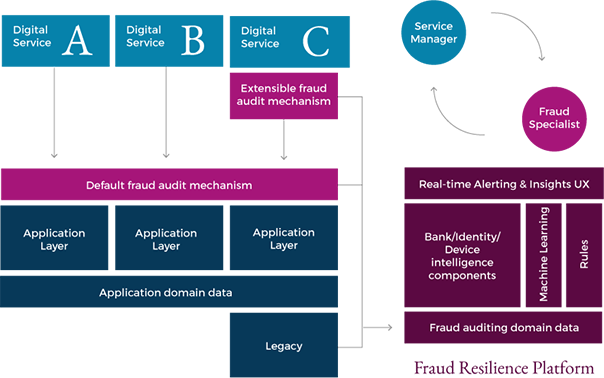 Operationally, the following fraud-resilience practices must be established:
Operationally, the following fraud-resilience practices must be established:
- training & transition of fraud operations teams with new tools & practices
- data security & access concerns are resolved through tools and user interfaces, not done manually
- integrating fraud/risk teams into digital services, assessing services as they are created, working together to update / train models during normal operations
- establish process and governance for digital/fraud data capture for new services and tuning at every update to a system
Resilience in the face of change
Developing fraud resilient systems to their full potential requires the ‘baking in’ of fraud resilience to every part of the software delivery process. The goal today is that every service within every organisation should deliver this enhanced functionality at no additional cost.
A fully-mature implementation of fraud-resilient technology will allow its operators to automatically assess fraud risk for any given transactions across all their business areas by combining behaviour and business process data in such a way that the costs don’t outweigh the benefits
To accomplish this, fraud-prevention must become a “team sport” where everybody participates in order to distribute the effort, much as we’ve done with QA and Security over the past few years. For that to happen, organisations must make it a transparent process by making the technology around it both light-weight and de-facto.
Embarking on a journey to enact a cross-organisational fraud resilience programme begins and ends with the knowledge already embedded within your organisation. Achieving a fully mature capability won’t happen overnight with the introduction of new technologies. Rather, technology improvements in this area will drive improved knowledge and behaviours across the organisation. Chief amongst those is the ability to recognise and react to this world of everlasting change. The trick is to start today.